
Patrick Amadeus Irawan
About Me
I’m a PhD student at MBZUAI, advised by Alham Fikri Aji. My work investigates the understanding-generation gap in multimodal models and builds solutions to close it.
Before my PhD, I worked as a Research Engineer at Singapore Management University with Chong-Wah Ngo, where I focused on multilingual and multimodal interpretation. I started this path during my Bachelor’s in Computer Science at Institut Teknologi Bandung, working with Ayu Purwarianti on synthetically scaling explainable VQA data.
My goal is to build multimodal systems that perceive, reason, and generate grounded response over complex real-world inputs — not ones that get “lucky” on benchmarks by exploiting shortcuts.
Research Interests
Multimodal models often appear to understand an image well when asked to describe it in dominant modality (e.g. text). But when the same model is asked to use that understanding to generate in non-dominant modality, like images or video, it fails on multiple aspects. My research starts by diagnosing where and why this breakdown happens, then works on the solutions that minimize such discrepancy.
Understanding
I study how models decide what to attend to, and why they over-rely on language signals while underusing visual inputs. This leads to shortcut learning, hallucination, and weak grounding across different settings — biased visual grounding under semantically-aligned perturbations (ConfusedTourists), fragile perceptual attention exposed through counting tasks (CountingTricks), and domain gaps that degrade even high-level understanding (SeeingCulture), and its reasoning elicitation quality (Synthetic-VQA-NLE).
Generation
These failure modes point toward where to intervene. I work on post-training methods that recover missing abilities and strengthen cross-modal alignment using adaptive distillation. LinguDistill shows that language ability degrades during visual training and that distillation can recover it, confirming the gap is real and empirically addressable. On the generation side, I am currently working on world model evaluation for plan-action consistency and memory-based VLMs to achieve better grounding robustness over out-of-distribution data.
Evaluation
Measuring progress on this gap also requires evaluation setups that are faithful to real-world conditions. I design benchmarks that stress-test model behavior under distribution shifts, missing modalities, and limited resources (WorldCuisine, SEACrowd, DataRubrics), so that improvements on the generation side can be tracked reliably and at scale.
Updates
- [Apr. 2026] LinguDistill is out on arXiv. We study how selective cross-modal distillation can recover linguistic ability in VLMs while preserving multimodal competence 🧠
- [Feb. 2026] 2 papers accepted to CVPR 2026! M4-RAG gets in as a main paper, and Vision Language Models are Confused Tourists appears in findings 🎉
- [Nov. 2025] Our study exposing the confusion of VLMs in cultural-conflict visual scenarios, Vision Language Models are Confused Tourists, is up on arXiv 🧳
- [Dec. 2025] M4-RAG is out on arXiv! We present an evaluation of how multimodal knowledge enrichment helps models tackle multilingual queries. Spoiler: it does not always help… 🤯
- [Oct. 2025] Entropy2Vec got accepted into MRL Workshop @ EMNLP 2025 🌐🇨🇳
- [July 2025] Seeing Culture Benchmark is accepted to EMNLP 2025 🇨🇳 On to the next one with the SMU Multimedia team 💪
- [May. 2025] DataRubrics is now on arXiv! We propose a unified scorecard to evaluate data quality on multi-faceted metrics 📊
- [Apr. 2025] WorldCuisines receives Best Theme Paper at NAACL 2025 🎉🌏🍽️
- [Mar. 2025] Admitted to the Fall 2025 cohort of the MBZUAI PhD program in NLP 📚
- [Jan. 2025] WorldCuisines and ProxyLM are accepted to NAACL 2025 🇺🇸🎖️
- [Nov. 2024] My first first-author paper, Towards Efficient and Robust VQA-NLE Data Generation with Large Vision-Language Models, is accepted to COLING 2025 🎉
- [Oct. 2024] WorldCuisines, the largest multicultural VL food benchmark, is released. Honored to co-lead the project 🥘
- [Sep. 2024] SEACrowd is accepted to EMNLP 2024 🇺🇸
Publications
2026
-
 Preprint
Preprint, 2026.Proposes a selective distillation strategy to recover linguistic competence in VLMs without giving up multimodal capability.
Preprint
Preprint, 2026.Proposes a selective distillation strategy to recover linguistic competence in VLMs without giving up multimodal capability. -
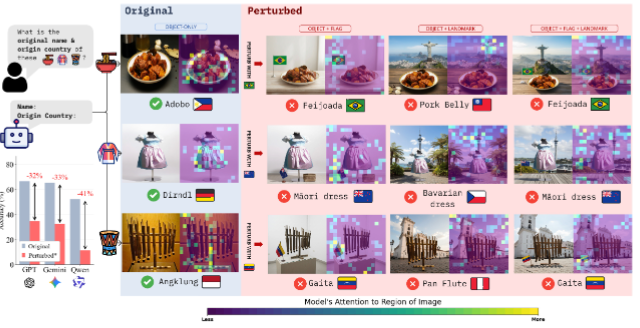 CVPR 2026 Findings
Computer Vision and Pattern Recognition Conference (CVPR), 2026 Findings.Studies how VLMs misread culturally conflicting visual situations, exposing grounding failures that are invisible to standard benchmarks.
CVPR 2026 Findings
Computer Vision and Pattern Recognition Conference (CVPR), 2026 Findings.Studies how VLMs misread culturally conflicting visual situations, exposing grounding failures that are invisible to standard benchmarks. -
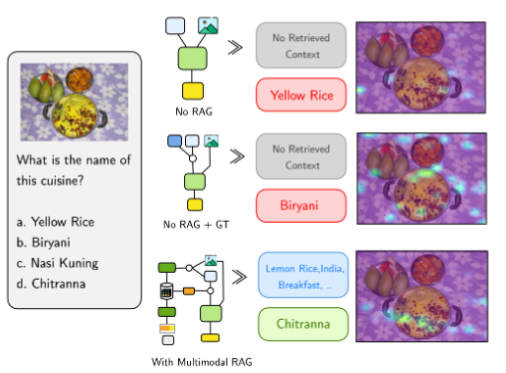 CVPR 2026
Computer Vision and Pattern Recognition Conference (CVPR), 2026.Evaluates whether multimodal retrieval actually helps multilingual and multicultural question answering at scale, and where it fails.
CVPR 2026
Computer Vision and Pattern Recognition Conference (CVPR), 2026.Evaluates whether multimodal retrieval actually helps multilingual and multicultural question answering at scale, and where it fails.
2025
-
 EMNLP 2025
Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025.Builds a benchmark for culture-sensitive visual reasoning and grounding, pushing evaluation beyond object recognition into contextual interpretation.
EMNLP 2025
Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025.Builds a benchmark for culture-sensitive visual reasoning and grounding, pushing evaluation beyond object recognition into contextual interpretation. -
 MRL @ EMNLP 2025
Entropy2Vec: Crosslingual Language Modeling Entropy as End-to-End Learnable Language RepresentationsMultilingual Representation Learning Workshop at EMNLP, 2025.Introduces entropy-based crosslingual representations that treat language modeling uncertainty as an end-to-end learnable signal.PDF Poster
MRL @ EMNLP 2025
Entropy2Vec: Crosslingual Language Modeling Entropy as End-to-End Learnable Language RepresentationsMultilingual Representation Learning Workshop at EMNLP, 2025.Introduces entropy-based crosslingual representations that treat language modeling uncertainty as an end-to-end learnable signal.PDF Poster -
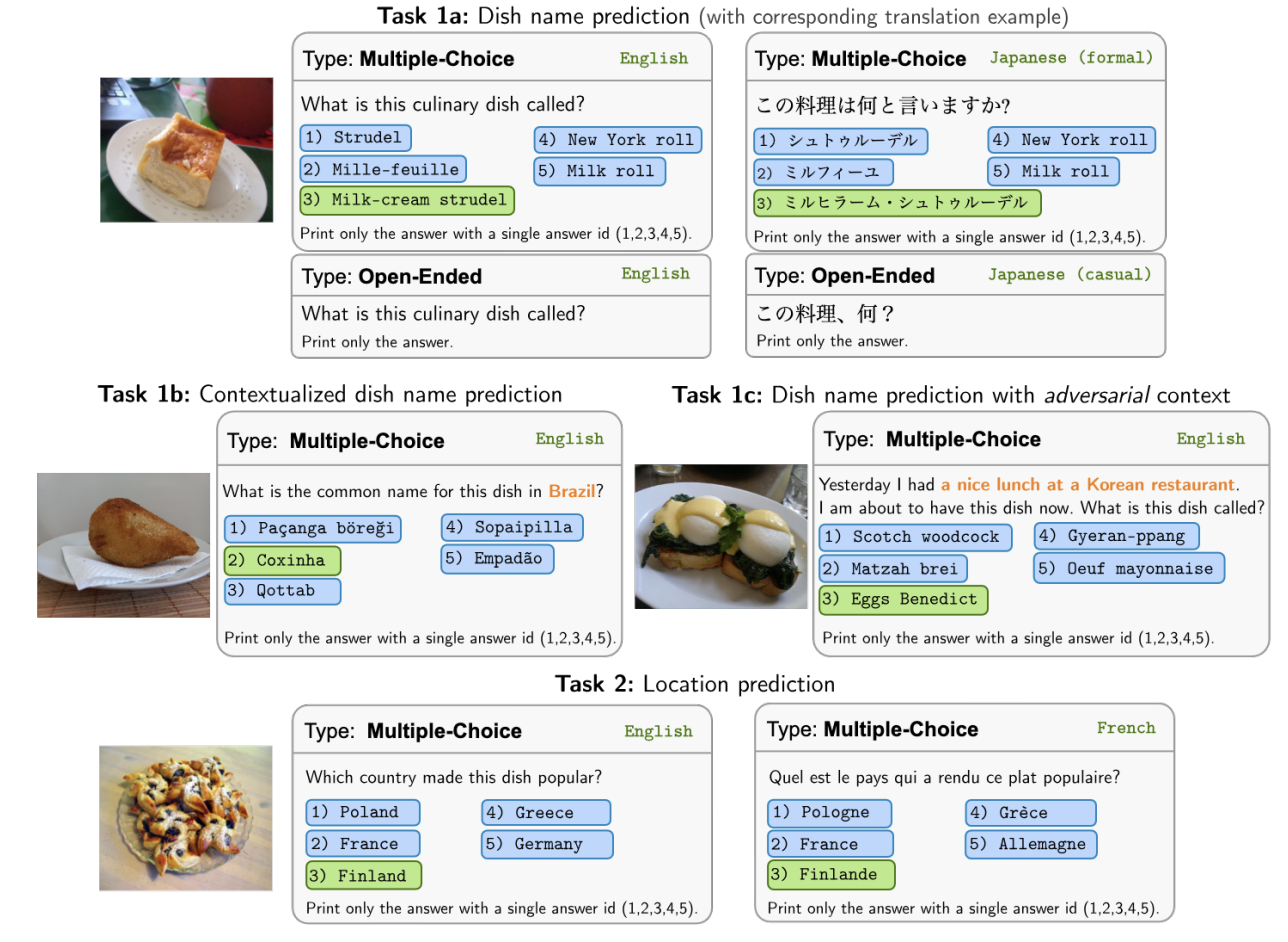 NAACL 2025
North American Chapter of the Association for Computational Linguistics (NAACL), 2025.Co-leads a benchmark that tests multilingual and multicultural VQA through food, culture, and visual context rather than English-centric priors.
NAACL 2025
North American Chapter of the Association for Computational Linguistics (NAACL), 2025.Co-leads a benchmark that tests multilingual and multicultural VQA through food, culture, and visual context rather than English-centric priors. -
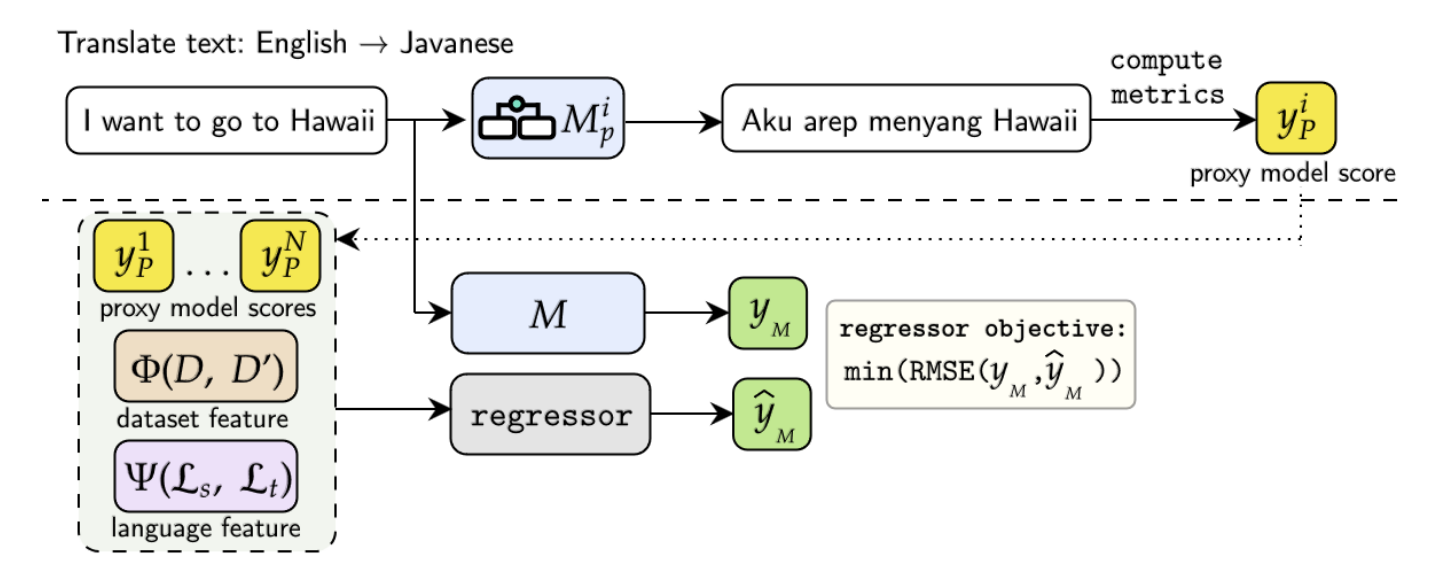 NAACL 2025
North American Chapter of the Association for Computational Linguistics (NAACL), 2025.Predicts multilingual model performance with cheaper proxy models, reducing evaluation cost when exploring large design spaces.
NAACL 2025
North American Chapter of the Association for Computational Linguistics (NAACL), 2025.Predicts multilingual model performance with cheaper proxy models, reducing evaluation cost when exploring large design spaces. -
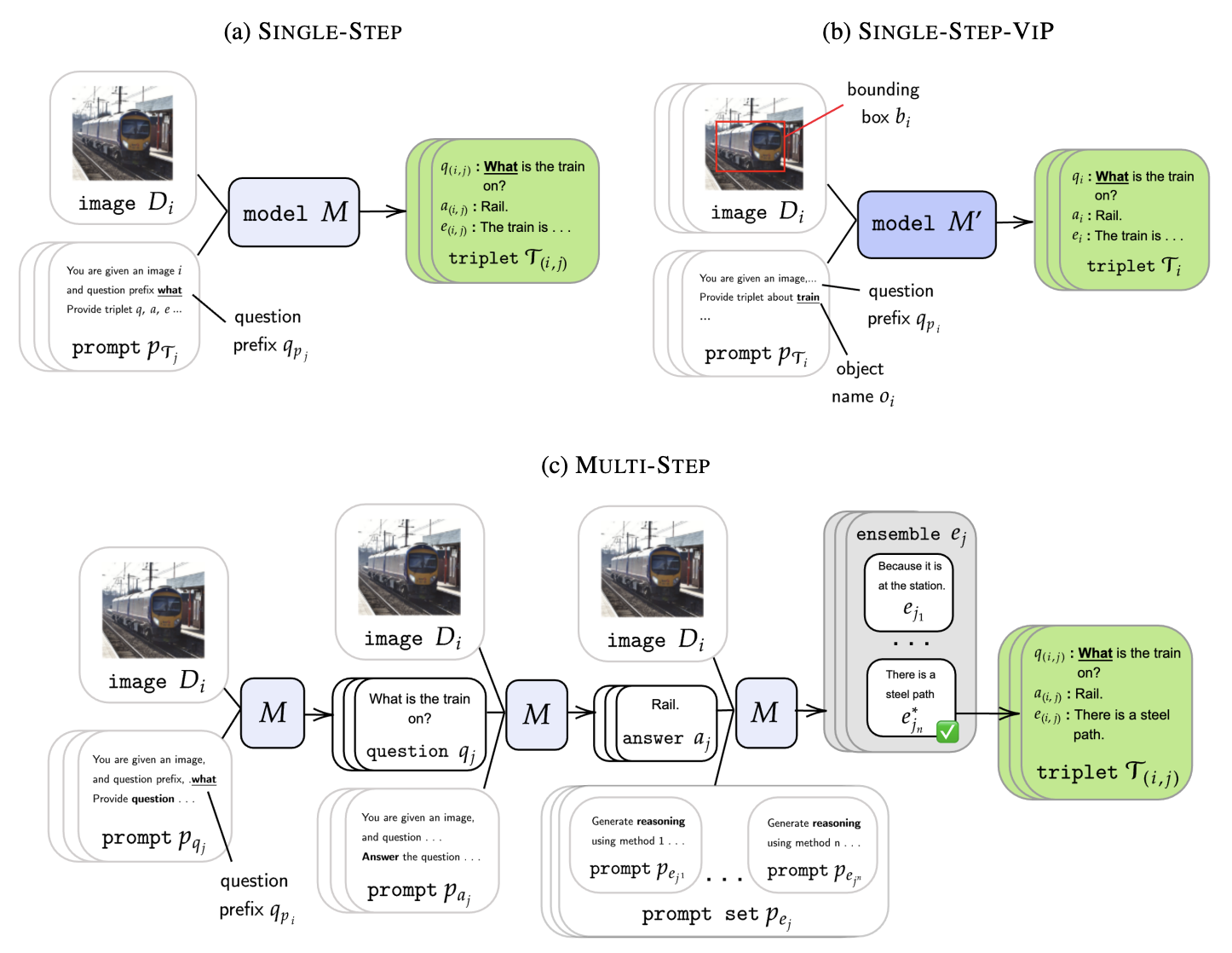 COLING 2025
International Conference on Computational Linguistics (COLING), 2025.Develops a more efficient pipeline for generating VQA explanations with VLMs, improving synthetic supervision for grounded reasoning.
COLING 2025
International Conference on Computational Linguistics (COLING), 2025.Develops a more efficient pipeline for generating VQA explanations with VLMs, improving synthetic supervision for grounded reasoning. -
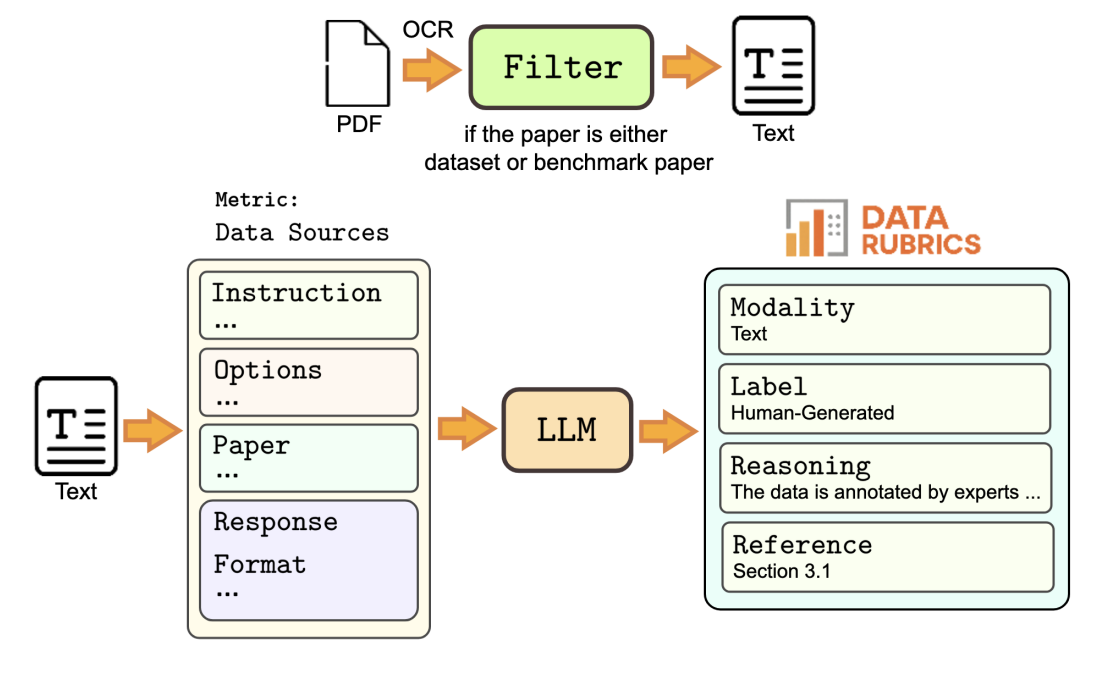 Preprint
Preprint, 2025.Proposes an automated scorecard for dataset quality and accountability, making data auditing more systematic and comparable.
Preprint
Preprint, 2025.Proposes an automated scorecard for dataset quality and accountability, making data auditing more systematic and comparable.
2024
-
 EMNLP 2024
Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024.Contributes to a multilingual multimodal data hub and benchmark suite centered on Southeast Asian languages, expanding evaluation beyond high-resource settings.
EMNLP 2024
Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024.Contributes to a multilingual multimodal data hub and benchmark suite centered on Southeast Asian languages, expanding evaluation beyond high-resource settings. -
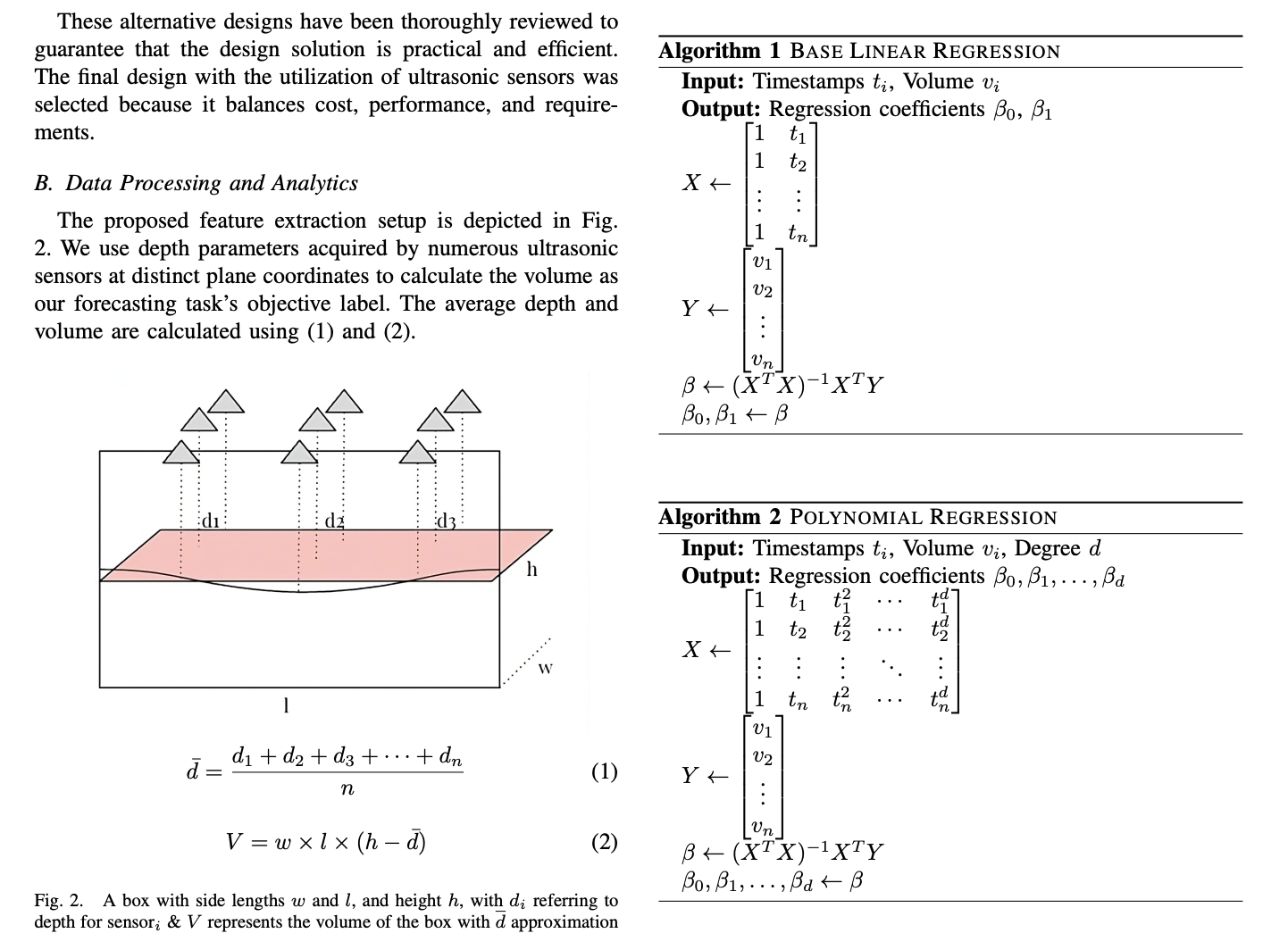 APSIPA ASC 2024
Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2024.Applies machine learning and sensor systems to real-world stock monitoring, showing the engineering side of my research background.PDF Oral
APSIPA ASC 2024
Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2024.Applies machine learning and sensor systems to real-world stock monitoring, showing the engineering side of my research background.PDF Oral
Experience & Service
Selected Experience
- Research Engineer @ Singapore Management University (2025 - 2025)
- Software Engineer @ IT Bauschmiede (2024 - 2025)
- Data Scientist Intern @ Supertype (2023 - 2023)
- Software Engineer Intern @ Blibli (2022 - 2022)
- Software Engineer Intern @ Ruangguru (2022 - 2022)